Keep the Gradients Flowing: Using Gradient Flow to Study Sparse Network Optimization
 SC-SDC Framework
SC-SDC FrameworkAbstract
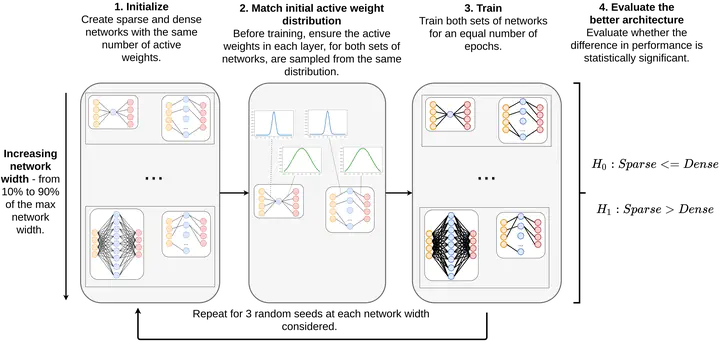
Training sparse networks to converge to the same performance as dense neural architectures has proven to be elusive. Recent work suggests that initialization is the key. However, while this direction of research has had some success, focusing on initialization alone appears to be inadequate. In this paper, we take a broader view of training sparse networks and consider the role of regularization, optimization, and architecture choices on sparse models. We propose a simple experimental framework, Same Capacity Sparse vs Dense Comparison (SC-SDC), that allows for a fair comparison of sparse and dense networks. Furthermore, we propose a new measure of gradient flow, Effective Gradient Flow (EGF), that better correlates to performance in sparse networks. Using top-line metrics, SC-SDC and EGF, we show that default choices of optimizers, activation functions and regularizers used for dense networks can disadvantage sparse networks. Based upon these findings, we show that gradient flow in sparse networks can be improved by reconsidering aspects of the architecture design and the training regime. Our work suggests that initialization is only one piece of the puzzle and taking a wider view of tailoring optimization to sparse networks yields promising results.
Kale-ab Tessera
PhD Candidate
Kale-ab is a PhD student at the University of Edinburgh, working on Multi-Agent Reinforcement Learning (MARL).